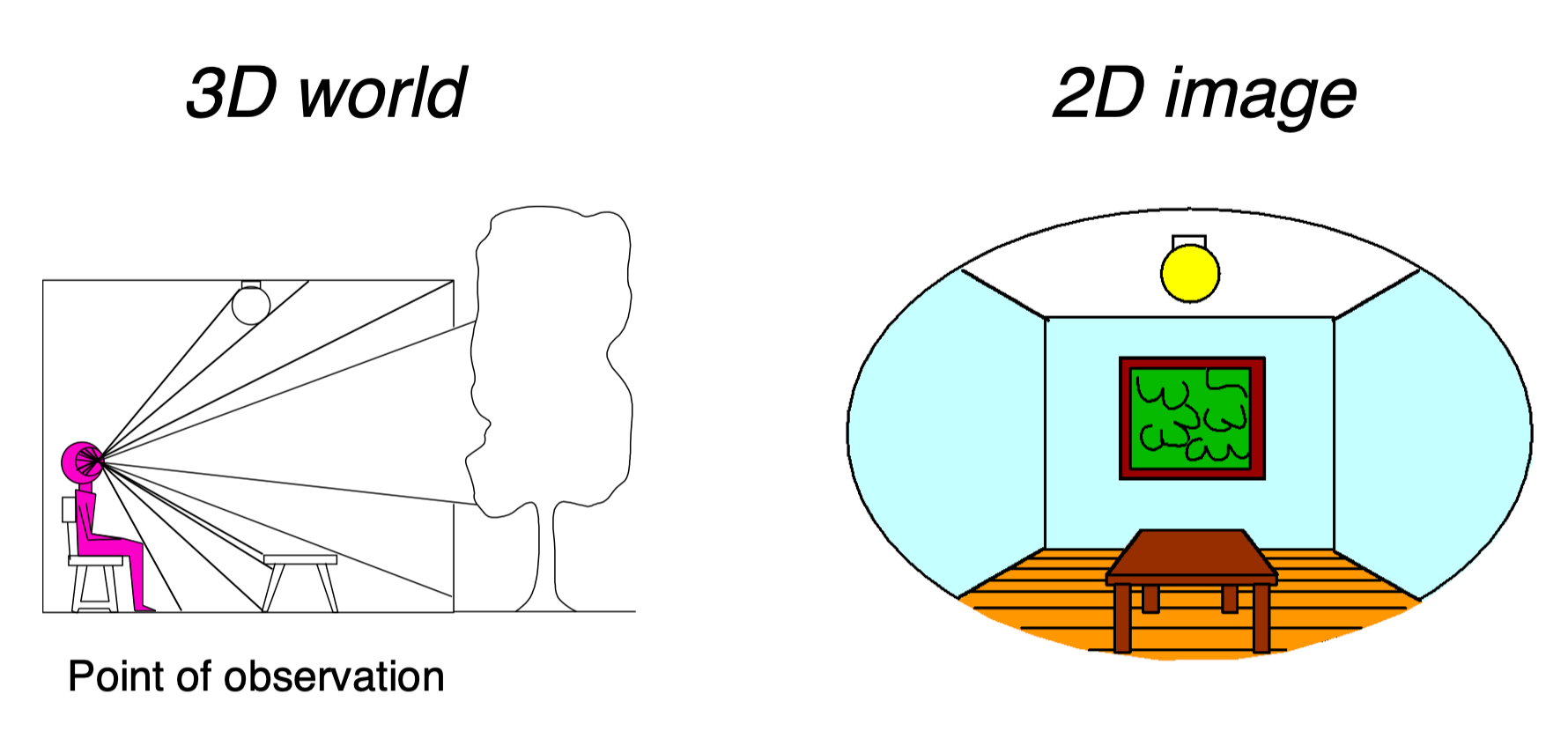
视频投影分享

前置知识
GPU 将图像渲染到屏幕上
物体与纹理
视频投影:将视频作为图片式贴在模型上
视频投影两个关键元素,模型与视频材质
物体组成
在虚拟世界中,所有物体由三角面构成(也有用四角形的,主流是三角形)
一般模型都是一张皮,内部是空心的
简单模型
纹理映射
将一张图片贴在模型上,模型就是一张皮,可以看成是地球仪表面平铺为世界地图,模型上每一个顶点对应纹理上的一个位置,顶点间用插值计算纹理颜色,纹理坐标使用的是百分比

将纹理图片(2k像素)贴在一个平面上

将纹理坐标和顶点坐标一一对应,剩下部分利用插值计算

随着取样点变少,图像失真程度越高,当取样点变成像素时,便可以将纹理图像完全贴在物体表面(自动过程),程序需要做的,将纹理图像的关键点坐标与物体点坐标对应上

在三维世界中,物体就是由自己所有的顶点以及每个顶点表示的颜色组成,颜色可以是自定义,也可以从图片材质中获取
3D 转换
我们能看到一个三维物体,我们需要四种元素,第一:眼睛;第二:大脑,对眼睛接受的数据进行处理;第三:三维世界,我们身处于三维世界中,比如地球,那我们就能描述我们的位置;第四:物体,否则看到就是透明空气了。
重新定义这四个概念,眼睛---相机,大脑---渲染器,三维世界---场景,物体---物体
看到场景物体的流程
1. 存在一个物体
物体本身具有顶点坐标(原始坐标数据:position),以及自己的移动(模型矩阵:modelMatrix)

茶壶建模完成后会有自己的顶点数据,以及每个顶点对应的颜色,茶壶可以自己进行旋转、移动和缩放,这三类操作会产生模型矩阵,用于计算。将茶壶自己元素坐标信息与模型矩阵加入到程序中,就相当于将茶壶经过转换,重置了茶壶上的每个顶点位置。
2. 存在一个相机,用于观察物体
相机位置、相机朝向和相机向上方向用来唯一确定相机具体方位,由这三个信息可组成视图矩阵(viewMatrix)
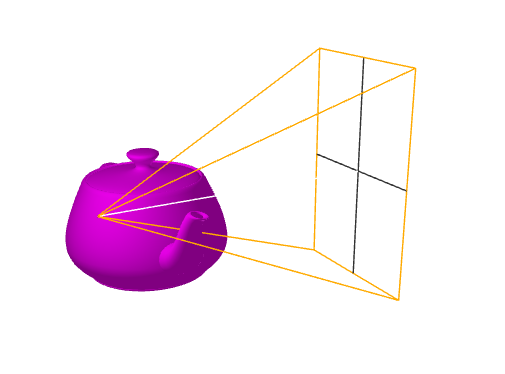
将视图矩阵加入程序中,就相当于锁定人眼了。
3. 根据相机参数的不同,得到不同的结构
比如:一个眼睛大,看得远,一个眼睛小,看得近,一个近视眼,一个远视眼。相机属性构成了投影矩阵 (projectionMatrix)
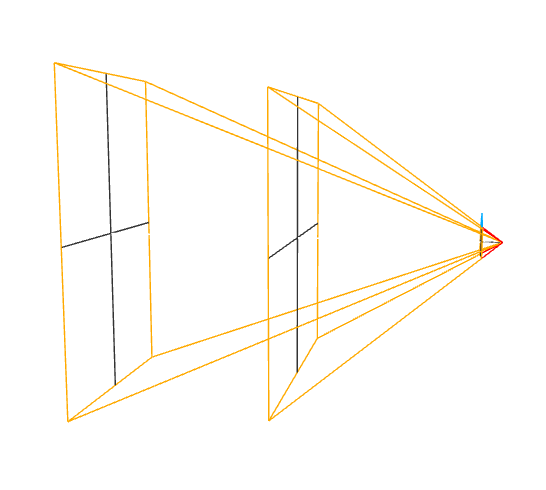
将投影矩阵加入到程序中,得到的就是从一个具体的人眼看到的三维世界
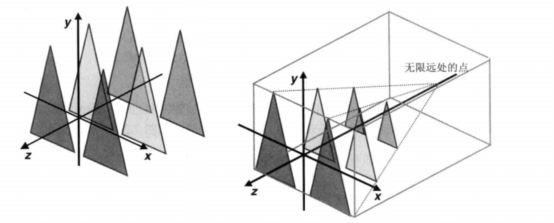
4. 最终得到规范立方体(canonical view volume)
在立方体内的物体就是我们看到的物体,立方体外的都可以剔除掉,那些都是视野外的。于此同时,由于视图矩阵和模型矩阵的加入,相机位于原点,看向 z 负轴。(规范立方体 (-1,-1,-1)到(1,1,1))
总结刚刚的过程,最终得到的物体坐标为
// projMatrix 投影矩阵,viewMatrix 视图矩阵,modelMatrix 模型矩阵 gl_position = projMatrix * viewMatrix * modelMatrix * position;
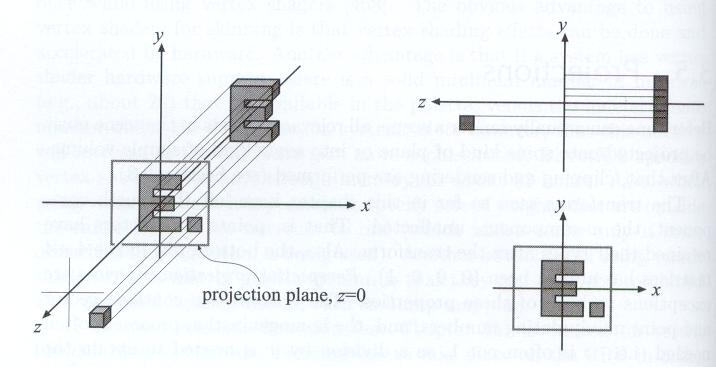
5. 由最终三维场景到二维图像
规范立方体得到了,z 坐标 从 1 到 -1 ,z 坐标代表这个物体深度。好似从前往后发射射线,碰到的第一个点就将其颜色赋值在平面上,最终形成二维图片
视频投影分析
关键:将视频纹理与模型上对应的顶点一一对应起来
1. 建立与现实一致的虚拟世界
模型比例与现实保持一致;投影的相机所处位置,参数,朝向,向上方向保持一致
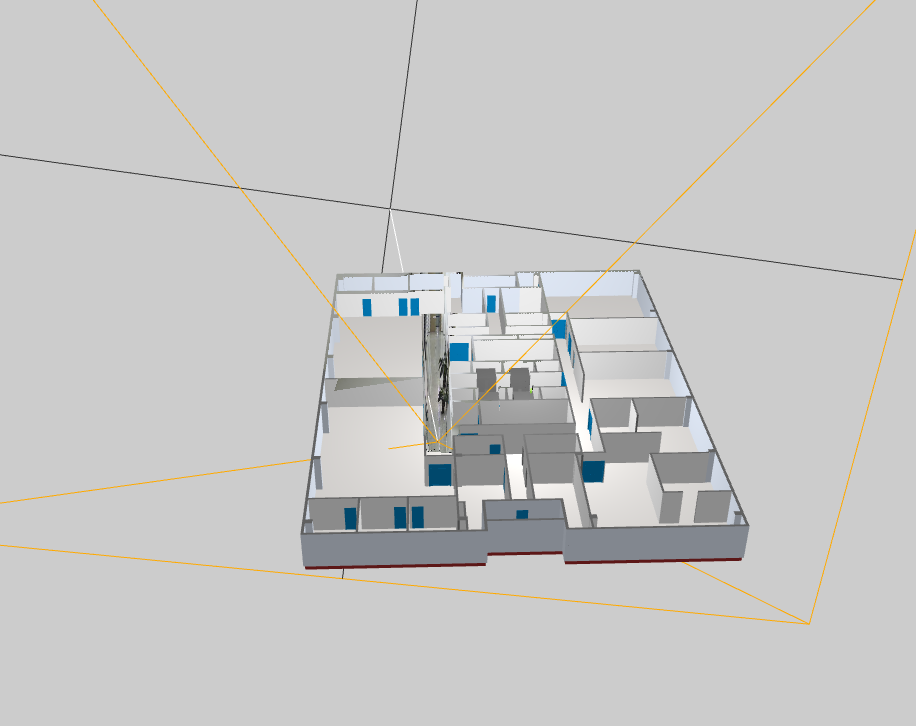
2. 获取视频纹理,分析投影过程
目前整个场景有两个相机,一个是主相机,就是上帝视角的这个相机;另一个是用作投影的相机,这里就叫投影相机。
首先,先获取到视频作为纹理对象,可以直接将视频看作一张图片,这里叫投影图,投影图就是投影相机拍出来的,因此,投影相机看到的二维图像就是投影图
现在我们可以得到三个图
- 上帝视角图
- 投影相机视角图
- 视频中的投影图
其中,投影相机视角图 = 视频投影图 (等式 1),2 = 3
因此,现在我们求出投影相机与模型产生的交点,并且根据 “等式1” 找到这个点的颜色,并将颜色赋值上去,最终便得到视频投影效果
投影相机看到的视角图

真实世界摄像机的视角图

一一对应上,最终完成
3. 关键代码解析
- 顶点处理
// 获取投影相机看到的标准立方体 c_Position = u_ProjectionMatrix * u_ViewMatrix * modelMatrix * vec4( position, 1.0 ); // 遍历模型上的每个点 gl_Position = projectionMatrix * modelViewMatrix * vec4( position, 1.0 );
- 颜色处理
// 投影相机计算出的 c_Position 处于 (-1,-1,-1)到(1,1,1)标准立方体中,z 是深度,x,y需要转换区间到 0-1(纹理坐标) vec4 c_Uv4 = c_Position / c_Position.w; c_Uv4.xyz = vec3( c_Uv4.xyz + 1.0) / 2.0; // 根据投影相机看到的顶点找视频图的对应位置的像素并赋值 gl_FragColor = texture2D(mapPicture, c_Uv4.xy);


